Oct252025

Oct252025
docker进阶_docker-compose

Docker-compose
为什么使用docker-compose
官方介绍
Compose 是一个用于定义和运行多容器 Docker 应用程序的工具。使用 Compose,您可以使用 YAML 文件来配置应用程序的服务。然后,使用一个命令,您可以从您的配置中创建并启动所有服务。Compose 适用于所有环境:生产、登台、开发、测试以及 CI 工作流程。
Compose 具有用于管理应用程序整个生命周期的命令:
启动、停止和重...阅读全文
Oct222025
html5 画布时钟效果
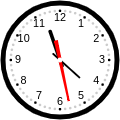
网上看到个时钟效果,感觉挺好看,转了来,具体通过html5画布技术实现的,效果图如下:
具体 html 代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>html5 时钟效果</title>
</head>
<body>
<canvas id="dom" width="120" height="120"></canvas>
<script type="text/j...阅读全文
Oct222025

Oct202025

Oct192025
Swoole实践:4-使用Swoole实现在线聊天
在线web聊天功能是基于WebSocket协议实现的,Swoole从1.7.9开始就增加了内置的WebSocket服务器支持,通过几行PHP代码就可以写出一个异步非阻塞多进程的WebSocket服务器。今天我给大家讲解如何使用Swoole实现一个简易的聊天功能。
准备
请按照本站Swoole系列文章:Swoole实验室,搭建好项目,并安装Swoole扩展。Swoole版本建议在1.8+,当然2.x,4.0都可以。
如果您是新访客,请先参考本站文...阅读全文
Oct022025
各大网站CSS代码初始化集合

css代码之所以初始化,是因为能尽量减少 各浏览器之间的兼容性问题!
腾讯QQ官网 样式初始化
body,ol,ul,h1,h2,h3,h4,h5,h6,p,th,td,dl,dd,form,fieldset,legend,input,textarea,select{margin:0;padding:0}
body{font:12px"宋体","Arial Narrow",HELVETICA;background:#fff;-webkit-text-size-adjust:100%;}
a{color:#2d374b;text-decoration:none}
a:hover{color:#cd0200;text-decorat...阅读全文
Sep272025
微信图片禁止外链 此图片来自微信公众平台未经允许不可引用

问题:
我的项目中要显示采集来自微信公众平台的图片未经允许不可引用。怎么办?
做项目时,采集到的微信图片在项目中不可引用,将<img>标签中的data-src 替换为src,将微信尾部?wx_fmt=jpeg去除
然后三种方法选其一:
1>图片地址前缀加上http://read.html5.qq.com/image?src=forum&q=5&r=0&imgflag=7&imageUrl=图片地址(貌似不可用了)
2>在head中加...阅读全文
Aug252025
python黑帽子(第五章)
对开源CMS进行扫描
import os
import queue
import requests # 原书编写时间过于久远 现在有requests库对已经对原来的库进行封装 更容易调用
import threading
# 设置线程
threads = 10
# 指定网站
target = ""
# 指定本地扫描路径
directory = ""
# 无效文件的后缀
filters = [".jpg", ".gif", ".png", ".css"]
# 切换路径
os.chdir(directory)
# 实例化queue
web_paths = queue.Queue...阅读全文
Aug252025
python黑帽子(第二章)
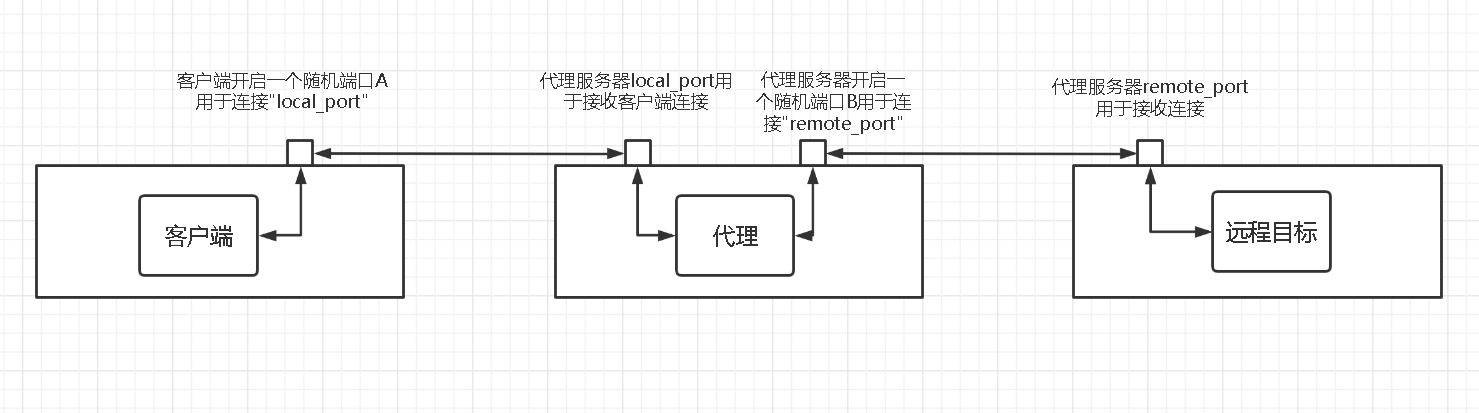
TCP客户端
在渗透测试工程中,我们经常会遇到需要创建一个TCP客户端来连接网络、发送垃圾数据、进行模糊测试等任务的情况。但是所处环境不具备丰富的网络工具,下面是一个简单的TCP客户端
import socket
# 要连接目标的ip和端口
target_host = '127.0.0.1' # ip或者域名
target_port = 1111
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((target_host, t...阅读全文